The IUPAC International Chemical Identifier – InChI
*
Stephen R. Heller and Alan D. McNaught
Division of Chemical
Nomenclature and Structure Representation, International Union of Pure and
Applied Chemistry (IUPAC)
The ability to represent uniquely a chemical compound is a fundamental requirement for storage or transmission of chemical information. We define compounds by their molecular structure, as typically shown in 2D diagrams or stored in computers as ‘connection tables’. Pronounceable names have been developed for oral and written communication, ranging from the trivial, containing no structural information, to completely systematic names, which can be “de-coded” to yield the original structure. However, the application of systematic nomenclature to complicated structures is not for the faint-hearted; it requires expert knowledge of elaborate systems of nomenclature rules. The use of systematic nomenclature to convey information about the increasingly complex molecular systems handled by today’s chemists is both laborious and inefficient.
IUPAC, the International Union of Pure and Applied Chemistry (www.iupac.org), has long been involved in the development of systematic and standard procedures for naming chemical substances on the basis of their structure. The resulting rules of nomenclature, while covering almost all compounds, were designed for text-based media. IUPAC has now developed a means of representing chemical substances in a format more suitable for digital processing, involving the computer processing of structural information (connection tables).
Over the past decade, with the ever-increasing reliance on computer processing by chemists, it became evident to many within IUPAC that this organization should develop methods of nomenclature that can be interpreted by computers, or more precisely, by computer algorithms. In particular it was felt that while IUPAC had stressed conventional chemical names/nomenclature for chemist-to-chemist communication in the 20th century, continued progress into the 21st century required new, chemist-to-computer approaches to the problem of chemical identification. This led to the initiation of a new program, aiming to create a method to generate a freely available, non-proprietary identifier for chemical substances that could be used in printed and electronic data sources. This would enable easier linking of diverse data compilations and unambiguous identification of chemical substances. A description of the project and its development can be found on the IUPAC website at http://www.iupac.org/projects/2000/2000-025-1-800.html The technical development was carried out primarily at the US National Institute of Standards and Technology (NIST), and the product is referred to as the IUPAC International Chemical Identifier (InChI).
InChI is not a registry system. It does not depend on the existence of a database of unique substance records to establish the next available sequence number for any new chemical substance being assigned an Identifier. Instead, it is simply the transformation of the chemical structure itself to a string of characters by algorithms. The conversion of structural information (in the form of a ‘connection table’) to the Identifier is based on a set of IUPAC structure conventions, and rules for normalization and canonicalization (conversion to a single, predictable sequence) of an input structure representation. The resulting InChI label is simply a series of characters that serve to uniquely identify the compound from whose structure it was derived. This conversion of a graphical representation of a chemical substance into the unique InChI label can be carried out automatically by any organization anywhere in the world, and the facility can be built into any chemical structure drawing program. InChI labels are completely transferable between organisations or individuals and can be created from existing collections of chemical structures.
While the ‘theory’ needed for conversion of a structure to a unique string of characters has been known for a long time, when work on InChI began there were no freely available unique representations for compound identification, nor was the development of such representations being actively discussed. Thus before active development could proceed, a precise specification of requirements was wanted, and the following five characteristics were identified as needed for such an identifier:
1. The structure of the compound of interest can be drawn using common conventions
2. The identifier is derived directly from the structure by an algorithm
3. Exactly one identifier is associated with a given structure – i.e., different structures give different identifiers
4. The identifier works for a large fraction of all ‘drawable’ chemical substances.
5. The identifier must be openly available
The InChI was developed with these characteristics in mind. To be as precise and broadly applicable as desired it uses a layered format to represent all available structural information relevant to compound identity. InChI layers are listed below. Additional layers, such as crystal data, can be naturally added, making the InChI extensible and robust. Each layer in an InChI representation contains a specific type of structural information. These layers, automatically extracted from the input structure, are designed so that each successive layer adds additional detail to the Identifier. The specific layers generated depend on the level of structural detail available and whether or not tautomerism is allowed. Of course, any ambiguities or uncertainties in the original structure will remain in the InChI.
This layered structure design offers a number of advantages. If two structures for the same substance are drawn at different levels of detail, the one with the lower level of detail will, in effect, be contained within the other. Specifically, if one substance is drawn with stereo-bonds and the other without, the layers in the latter will be a subset of the former. The same will hold for compounds treated by one author as tautomers and by another as exact structures with all H-atoms fixed. This can work at a finer level. For example, if one author includes double bond and tetrahedral stereochemistry, but another omits the latter, the latter InChI will be contained in the former.
The InChI layers are:
1. Formula (standard Hill sorted)
2. Connectivity (no formal bond orders)
a. disconnected metals
b. connected metals
3. Isotopes
4. Stereochemistry
a. double bond (Z/E)
b. tetrahedral (sp3)
5. Tautomers (on or off)
Charges are not part of the basic InChI, but rather are added at the end of the InChI string.
For those interested in the details, examples of InChI representations are given below. It is important to recognize, however, that InChI strings are intended for use by computers and end users need not understand any of their details. In fact, the open nature of InChI and its flexibility of representation, after implementation into software systems, may allow chemists to be even less concerned with the details of structure representation by computers.
Several illustrative examples of the conversion of structural drawings to InChI are given in Figures 1-3. InChI strings are given just above the Figure title and numbers shown in the diagram are found and used internally for producing a ‘canonical’ (unique) representation.
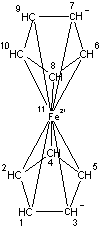
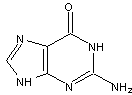
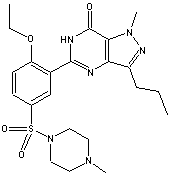
Figures 1-3 show the InChI for ferrocene, guanine, and Viagra with optionally included connected metal (Figure 1) and tautomers off (Figures 2 and 3).
|
|
|
|
|
||
|
Input |
Canonical numbering |
Input |
Canonical numbering |
||
|
Disconnected metal |
Connected metal |
||||
|
InChI=1/2C5H5.Fe/c2*1-2-4-5-3-1;/h2*1-5H;/q2*-1;+2/rC10H10Fe/c1-2-4-5-3(1)11(1,2,4,5)6-7(11)9(11)10(11)8(6)11/h1-10H |
|||||
|
Figure 1. InChI for ferrocene |
|||||
|
|
|
|
|||
|
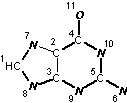
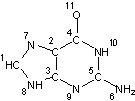
Input structure |
Mobile H canonical numbering. Attachment points of 4 mobile H and changeable bonds are in bold |
Fixed H canonical numbering |
|||
|
InChI=1/C5H5N5O/c6-5-9-3-2(4(11)10-5)7-1-8-3/h1H,(H4,6,7,8,9,10,11)/f/h8,10H,6H2 |
|||||
|
Figure 2. InChI for guanine |
|||||
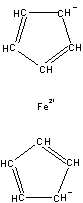
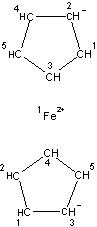
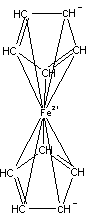
|
|
|
|
|
Input structure |
Mobile H canonical numbering. Attachment points of 1 mobile H and changeable bonds are in bold |
Fixed H canonical numbering |
|
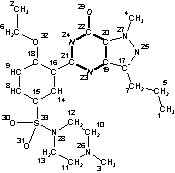
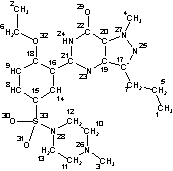
InChI=1/C22H30N6O4S/c1-5-7-17-19-20(27(4)25-17)22(29)24-21(23-19)16-14-15(8-9-18(16)32-6-2)33(30,31)28-12-10-26(3)11-13-28/h8-9,14H,5-7,10-13H2,1-4H3,(H,23,24,29)/f/h24H |
||
|
Figure 3. InChI for Viagra (sildenafil) |
||
|
|
|
|
|
|
Input structure |
Preprocessed structure (this made the Mobile H layer for ionized and neutral acids same) |
Mobile H canonical numbering. Attachment points of 2 mobile H and changeable bonds are in bold |
Fixed H canonical numbering |
|
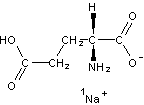
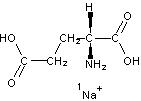
InChI=1/C5H9NO4.Na/c6-3(5(9)10)1-2-4(7)8;/h3H,1-2,6H2,(H,7,8)(H,9,10);/q;+1/p-1/t3-;/m1./s1/fC5H8NO4.Na/h7H;/q-1;m |
|||
|
Figure 4. InChI for monosodium glutamate (MSG) |
|||
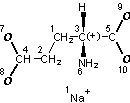
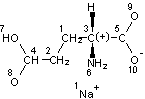
The layers in the InChI string are separated by the ‘/’ character followed by a lowercase letter (except for the first layer, the chemical formula), with the layers arranged in predefined order. In the examples in Figures 1-4 the following segments are included:
/ Chemical formula
/c Connectivity-1.1 (excluding terminal H)
/h Connectivity-1.2 (locations of terminal H, including mobile H attachment points)
/q Charge
/p Proton balance
/t sp3 (tetrahedral) parity
/m Parity inverted to obtain relative stereo (1 = inverted, 0 = not inverted)
/s Stereo type (1 = absolute, 2 = relative, 3 = racemic)
/f Chemical formula of the fixed-H structure if it is different
/h Connectivity-2 (locations of fixed mobile H)
/q Charge
/t sp3 (tetrahedral) parity
/m Parity inverted to obtain relative stereo (1 = inverted, 0 = not inverted, . = inversion does not affect the parity)
/s stereo type (1 = absolute, 2 = relative, 3 = racemic)
/r Chemical formula of “connected metal” structure.
/c Connectivity-3.1 (connected metal structure excluding terminal H)
/h Connectivity-3.2 (locations of terminal H, including mobile H attachment points)
The symbol “m” inside a layer (layer /q on Figure 4) means “same as in the preceding”. Repeating stereochemical segments inside Mobile-H layer are omitted. Therefore, in the Mobile-H layer: “/q-1;m” stands for “/q-1;+1/t3-;/m1./s1”
Each layer depends strictly on the layers preceding it, so one cannot compare two sublayers for different compounds. Parsing of the InChI string in order to extract layers for the purpose of comparing structures is based on the following.
/r divides InChI into disconnected and connected parts in this order.
Each of these parts (if present) has its formula segment and connections segment.
/f divides these parts into mobile-H and fixed-H parts in this order.
Each of these parts has a description of the locations of terminal H, the latter complementing the former.
/i divides these parts into normal and isotopic parts (/i is not present in the examples).
Each of these parts may contain segments describing stereochemistry.
Source code and an executable version of the structure-to-InChI conversion algorithm are freely available from the IUPAC InChI website at http://www.iupac.org/inchi.