Stephen R. Heller
and
Lewis H. Gevantman
The scientific community is currently
undergoing phenomenal changes in the
way it produces, compiles, and disseminates scientific
information and data. Much of it can now be managed by
computer. Similarly, bibliographic literature searching has
become routine using a variety of on-line systems
(see
box).
A newer activity that is starting to make its presence felt in
the scientific community is that of providing the scientist with
access to numerical data through a variety of automated
mechanisms. Several numerical data bases have emerged and are now
being used. However most of these data bases remain unique--some have search
and retrieval capabilities, but for the mostpart they remain
free-standing bodies of numerical data without connection to
one another.
A decade ago the idea of combining related numerical data bases
for the environmental science community (1) was activated first
at the National Institutes of Health and subsequently by the EPA.
Coordination with other government agencies led to a system of 22
data bases and software analysis programs entitled Chemical
Information System (CIS). This system, which is under private
operation, is available to the environmental scientist. However,
some of the newer computer capabilities and improved data
management designs are not available in the system.
A numerical data base is defined as a collection or compilation
of numerical data that describes either singular or multiple
physical parameters of a specified chemical substance. Generally,
the number of parameters and substances are limited. The data
base may have simply a listing of numbers or it may have search
and retrieval software for extracting the desired data value.
Some come with calculational capability for extrapolating or
interpolating values based on theoretical or empirical grounds.
Most of these data bases are free-standing and each may require
the use of a unique approach for extraction of the information
contained in the data base. This makes for the investment of
considerable time and effort on the part of the user to learn and
manipulate each data base. In addition, the data contained in
such data bases are culled from the scientific literature and
other sources with minimal attempt to evaluate the quality of the
data. Also, some data bases are created with little or no regard
for adding to or updating their capability. This tends to render
the data less useful with the passage of time
On-line dissemination
A better approach to on-line numerical data dissemination for environmental scientists has been initiated by Technical Database Services, Inc., (TDS, see box) in their Numerica system. In contrast to the individual free-standing bodies of data bases available to users, the Numerica system is one of a cluster of experimental data bases, each of which has been scrutinized and accepted by the data base developer for quality and timeliness. Although each data base comes from a different source, inconsistencies between data bases (primarily in the area of nomenclature) are resolved by the use of Chemical Abstracts Service (CAS) registry numbers. Furthermore, each part or data base is closely related to the, other so that the data can be checked for consistency within all data bases. Programs are available to round out an compare calculational versus expert mental values with further opportunity to extend the data into areas where no data exist. The search and retrieve strategies for accessing the data bases are also rendered in a consistent manner, so there is no need to learn how to use each data base. Consequently, the buildup of data bases clustered about a centralized theme such as environmental science presents a highly useful systems concept.
Highlights of how the Numerica system searches for specific
chemical properties data illustrate the system's utility in
meeting the needs of the environmental scientist. For example,
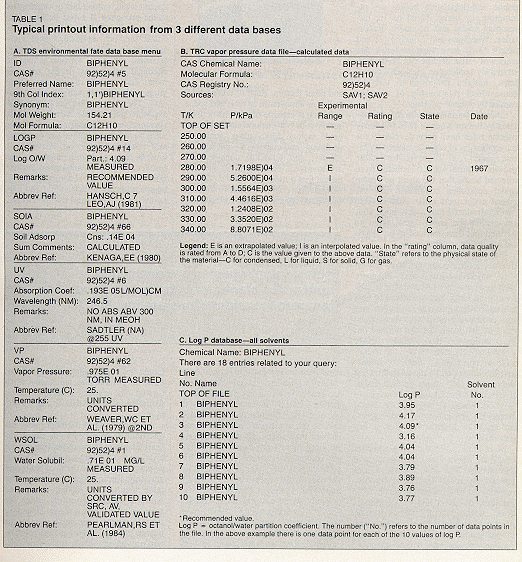
the chemical 1,l'-biphenyl (molecular formula C12.H10) has been
assigned CAS registry number 92-544. Access to the Numerica on-line system is achieved in the usual manner through a dial-up
telephone network, in this case Telenet.
What data base to use
Before beginning a search of Numerica data bases, one must check
to see which, if any, data base contains data on the chemical of
interest. This can be done by using SYNDEX, which contains an
index of CAS registry numbers, chemical names, synonyms, and TDS
data base tags. This allows the user to save both time and money
by avoiding systems that do not contain the needed data. The
results of the search show that numerical data on l,l'-biphenyl
can be found in the Thermodynamic Research Center Database, the
Carcinogenic Information Database for Environmental Substances
(CIDES) (see box), the Environmental Fate Database (EFDB) (2),
and the Log P and Related Parameters Database (3). Illustrative
excerpts from three of these data bases are shown in
Table 1. In
performing a search for data and information on 1,1'-biphenyl,
the first type of data to be searched is environmental fate data.
Yet another data base, CHEMEST, can be used to calculate many of
the parameters described in
Table 1. CHEMEST shows property
relationships and fills in for missing data.
It is hoped that the searches and displays shown have conveyed
the value of having high-quality data that are easily searched in
an on-line system. Numerica is a simple system to use, and having
the SYNDEX data base as a front end allows one to perform a quick
and efficient search of available data before even going into a
specific data base. Lastly, the ability or potential to compare
experimental and calculated data (e.g., in the TRC Datafile) is a
valuable resource.
Looking ahead
The future direction for Numerica is twofold. First, there is the
need to bring other useful and important data bases into the present
cluster. By integrating the new data with the
present files, an ever-increasing numerical data capability is
available to the user with a minimum investment of time and
effort. Second. the cluster of environmental data permits the
formation of other clusters of numerical data that may relate or
be completely independent of the environmental data. The option
to select the theme of the next cluster is obviously predicated
upon the availability of data bases and the ability of such data
bases to serve a need expressed by the user community.
For example, a new cluster aimed at chemical engineering,
chemical manufacture, and data that embrace chemical and
pharmaceutical concerns is a natural extension of the Numerica
system. Obvious relationships to the Physical Properties Data
System and other data bases would then promote the use of both
data clusters because of the need to satisfy data requirements of
a mutual nature. Similarly, a biologically oriented cluster would
again have implications for relating the contents of the new set
of data bases to the existing cluster. The flexibility and
advantages described for constructing clustered data bases are
believed to be clearly superior mechanisms for producing online
systems in the future.
References
(1) Heller, S. R.; Milne, G. W. A. Environ. Sci. Technol. 1979
13,798-803.
(2) Howard, P. H.; et al. J. Chem. Inf. Comp.Sci. 1982 22 38-44.
(3) Leo, A. J. J. Chem. Soc. Perkins Trans. 11,
1983,825-38.
Stephen R. Heller is a research leader in the model and data base
coordination laboratory of the Department of Agriculture,
Beltsville, Md.
Lewis H. Gevantman is a guest researcher at the National Bureau
of Standards in Gaithersburg, Md. He retired from federal
service after 17 years as program manager in the NBS Office of
Standard Reference Data.
{kind=link}
{kind=link}