New Access to Data from the Beilstein Institute: Beilstein Online and SANDRA
Stephen R. Heller
Agricultural Research Service
US Department of Agriculture
Beltsville, MD 20705
A sleeping giant has recently awakened and is likely to have a considerable effect on the daily activities of many organic chemists, other chemists and scientists who deal with and use chemical property data, and most importantly, on the activities of information scientists who have a need for chemical information. The Beilstein Institute for the Literature of Organic Chemistry, located in Frankfurt Germany, has begun to computerize their vast collection of scientific data associated with organic molecules.
The Beilstein Handbook for Organic Chemistry, which has evaluated data on chemicals reported in the literature dating back to 1830, is scheduled to go online on DIALOG early in 1988. The initial database will contain over 1.5 million chemical structures associated with chemical property and other evaluated data.
In conjunction with the online database there is already an IBM PC computer program, - SANDRA (Structure and Reference Analyzer), which is a quantum leap forward in searching for a chemical in the more than 300 printed volumes of the Beilstein Handbook. This article will describe the Beilstein computer readable files which will be online in 1988, as well as SANDRA.
BEILSTEIN ONLINE
The Beilstein Structure and Factual Data files will be two online computer files of considerable size and unique value to the chemical community. These two combined files are being called Beilstein Online and will be available in 1988, first on DIALOG, then on STN, and probably on other online systems later.
The Beilstein Structure file will be available both online, and for lease on tape for in-house use. The present intended policy of Beilstein is to make the Beilstein Factual file available only online. While the cost to the user community for the online version has yet to be established, it has been stated that those who do subscribe and continue to subscribe to the printed Handbook will receive a discount on their online use.
A FIRST LOOK
Beilstein Online will be a combined structure and data search system, of the type which the NIH/EPA CIS [1] first made available over a decade ago. However, that system was on a much smaller scale, with less evaluated data, and a narrower range of scientific data. [2]. To DIALOG users this means the ability to do true chemical structure searching for the first time.
As this article is being written, a number of chemical structure search systems are being evaluated by the Beilstein Institute, including DARC, HTSS, and a new system which the Beilstein Institute itself is developing. From the users' standpoint, the particular system chosen should not matter, since the capabilities of all these systems have similar qualities and properties.
The factual data search capabilities will use either DIALOG software or software developed by the Beilstein Institute for the needs of this factual database. The actual factual database will consist of two parts, the evaluated data and the non-evaluated data. All data from the 1830's through 1979 (corresponding to the printed Beilstein Handbook H. E-I, E-II, E-III, E-III/IV, E-lVand E-V Series) will be theoretically evaluated data. From 1980 onwards, the data will first be put online in a non-evaluated form, and as the data is critically evaluated, it will replace the non-evaluated data. This will enable the Beilstein database to be more up-to-date than it has been in the past.
For the evaluated data there will be two types of compounds, the Large Information Compounds (LIC) and the Small Information Compounds (SIC). LIC's, which comprise less than 5% of the total chemicals in the database, are chemicals which are very important in the chemical, pharmaceutical, agrochemical, and other fields of chemistry. For these LIC's, the online Beilstein database will have only a subset of all the information available for the compound. However, the Beilstein Handbook will continue to have all the information for each LIC. For the SIC's all the information in the Beilstein Handbook will be available online.
BEILSTEIN DATABASES--THE SYSTEM ANALYSIS
In late 1983 the Beilstein Institute initiated a study on how best to computerize the world's largest publicly available collection of factual and numerical chemical data. After a fifteenmonth study was completed, work started on the data input of both the chemical structure data and the factual and numeric data. The database is divided into two parts, a Structure File and a Factual File. The Structure File, hich is expected (in the initial database) to numberabout 1.5 million chemicals, will provide a complete topological structure representation for each chemical entry. The Factual File will contain some 7.5 million factual records of organic compounds dating back to 1830. Over 400 fields are defined in the Factual File, with more than 60 of these fields being numerical data fields.
BEILSTEIN STRUCTURE FILE
The Beilstein Structure file, called the Beilstein Registry Connection Table (BRCT), will be the largest collection of complete structure representations ever compiled. Complete means the inclusion of stereochemical representation within the BRCT. This differs from the current Chemical Abstract Service (CAS) Registry III structure database, which is totally two-dimensional, and has the stereochemical information only as a text descriptor. The other main difference is that the Beilstein "Registry" number, actually called the Lawson number, has structural meaning, whereas the CAS Registry Number (RN) is purely an-idiot number, assigned in a sequential fashion as articles are abstracted in the literature or new chemicals added to the database. When corrections are made in the CAS Registry system, a manual connection must be made between the latest revised CAS RN and the existing RN's. This means that a "corrected" CAS Registry Number has no logical or other type of connection to the original number, except that they are both nine-digit numbers.
BEILSTEIN STRUCTURE FILE DATA FIELDS
The BCRT consists of a required header field and a number of required and optional fields. The header field is a fixed-length record which contains information such as the length of the required and optional fields. Since the number of other fields are variable, the entire BCRT is of variable length.
The first of the two required fields is the Pi-bonding electron list, which specifies the number of valence electrons which contribute to any carbon bonds. The second required field is the From list, which specifies information on atom connections. There are eighteen optional fields. These include: the ring closure field, the atom field, the localized hydrogen field, the stereo-atom field, the stereo-bond list, the stereo-axis field, the non-default valence field, the localized charge field, the delocalized charge field, the localized unpaired valence electron (radical) field, the delocalized unpaired valence electron (radical) field, the abnormal mass in a known location field, the abnormal mass in an unknown location field, the hydrogen isotope in a known location field, the hydrogen isotope in an unknown location field, the mobile tautomer group field, the localized tautomer group field, and the supplementary descriptors field. These fields are defined and explained by Clemens Jochum, the Managing Director of the Computing Division of the Beilstein Institute, and President of the Beilstein Institute responsible for computing and databases, in further detail elsewhere. [3] Most of the meanings of these fields are self-evident from their names, and of course, the supplementary descriptors field is designed to cover any codes or text descriptors which cannot be described in any other required or optional fields in the BRCT.
THE BElLSTEIN FACTUAL DATABASE
From the point of view of the Beilstein Institute there are five types of databases:
1. Bibliographic
2. Referral
3. Numeric
4. Full-text
5. Factual
Factual means a database containing substances (chemicals) and the data associated or connected with the substances. Beilstein considers there are three main uses of a factual, substance oriented database. First is the simple retrieval of all the information for a chemical that the user specifies is wanted from the database. The second is the reverse of the first, namely that one may enter a particular piece of data and retrieve all substances with this property. The third, and potentially most valuable for the user, is the comparison, calculation, interpolation, or extrapolation of a property from the existing database. The latter is being explored for the future of the Beilstein database, although clearly some use of this capability is now being made by the Beilstein staff as they evaluate the data and properties going into the existing database and Hand book.
The Beilstein database contains all the physical and chemical data properties relevant to the organic compounds in the file. These properties are arranged in an ordered structure, with related information in close proximity. For example, all spectra come under class field 4.2.6, with a further breakdown of 4.6.1 for NMR, 4.2.6.1. 1 for a specific nucleus, 4.6.2 for ESR, and so forth. The entire set of major classes is shown in Figure 6. Each property listed has its own literature reference. There are two main types of property data in the factual database. For about 400 properties, the 70 I most important are given numerically, while the remainder are given only as literature references.
SANDRA
SANDRA, which stands for Structure and Reference Analyzer, is a recently released IBM PC DOS-based program (a Macintosh version is not expected in the near future) which takes a chemical structure you draw easily on the PC screen, and directs you to where to find references to that compound in the 300 volumes of the printed Beilstein Handbook. The program was written by Sandy Lawson, the managing director at the Beilstein Institute. It is a major advance in the tools created to help in looking up a chemical in the Beilstein Handbook. The well-structured Beilstein ordering and indexing system has been, and still is, a great barrier to the use of the more than 300 volumes of the Beilstein Handbook. Now, with one simple, easy to-use program it is possible for inexperienced organic chemists and even nonchemists to expertly find references in the Beilstein Handbook.
FIGURE I
SANDRA HELP COMMANDS
A Alternate Bond Order
B Backup User-defined Fragment
C Center Structure
D Decrease Size of Structure on Screen
E Enlarge Size of Structure on Screen
F Fischer cross
K Kill Structure without Backup
M Move Structure
N Number the Atoms
P Paint Screen after Erasing
Q Quit (end of structure input)
S Symbols on Atoms
W Without C-Symbols or Numbers X Bold Line
Y Dotted Line
Z Wavy Line
1 Single Bond (Default)
2 Double Bond
3 Triple Bond
Press any Key to Continue
That capability will impress anyone who has come within a meter of the Beilstein Handbooks volumes on the shelves in a library. I must say I felt like I was cheating when I first started to use the program. I wondered how something so easy and good could still be legal.
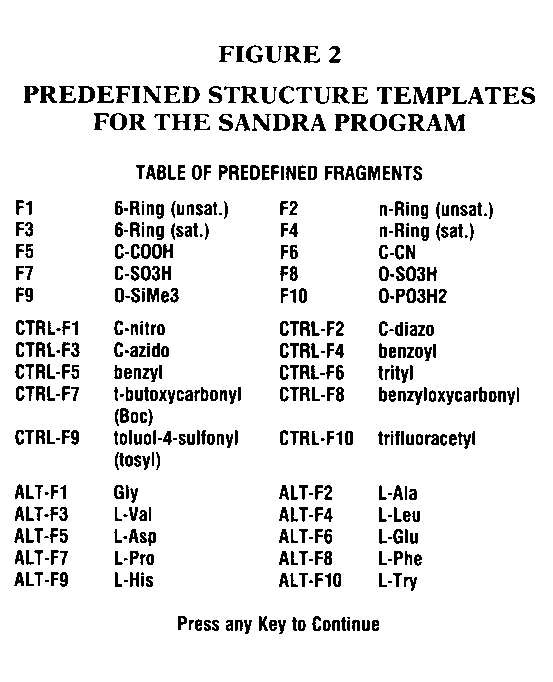
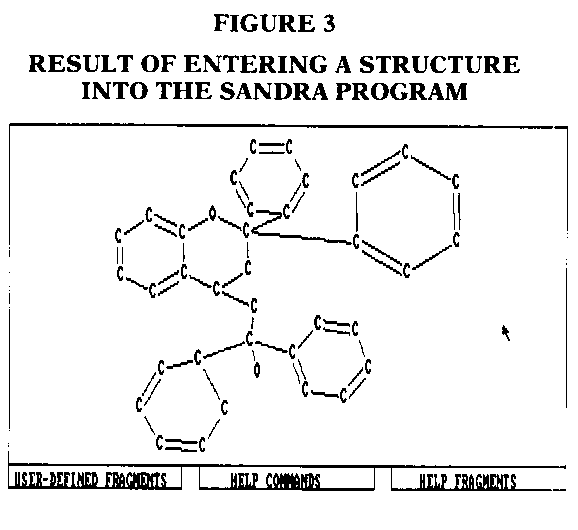
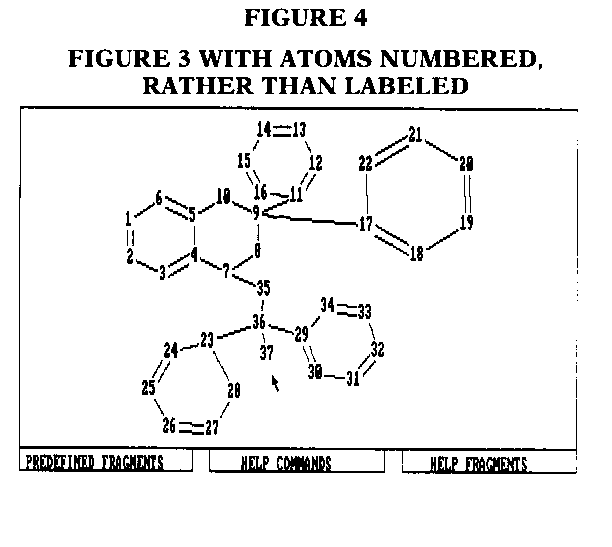
The program is easy to install, and the manual is detailed, with plenty of examples. It took me only a few minutes to load the program on my hard disk and start running. The program requires 256K memory, DOS 2.0 or higher, a Microsoft or equivalent mouse, and an IBM CGA or equivalent graphics adapter board with a resolution of 640 x 200 pixels. Version 1.0 of the program will not run if you have a Hercules graphics board, but a later version, due to be released by the middle of 1987 will work with the Hercules board. The flexible graphical structure input is easy to learn. If you forget a command, all you need to do is touch the mouse pointer to the "HELP COMMANDS" box, and immediately the list of commands, shown in Figure 1, pops onto the screen. There are thirty predefined structure templates, as well as the ability to create and store your own templates. The list of the thirty predefined fragments is shown in Figure 2. A sample structure is shown in Figure 3. This is what the structure looks like after input. To keep track of atoms it is possible to label them as well as number them. This option is shown in Figure 4. The analysis is performed after an acceptable structure is entered, by simply typing a, to quit the structure entry and 2 to start the analysis part of the program. The analysis takes from two to twelve seconds, depending on the computer (XT or AT or 386) and the complexity and size of the structure entered. I went the limit and was able to draw a 70-atom molecule, the maximum number of atoms allowed by the program. This 70-atom molecule took twelve seconds to come up with the correct pointers and page numbers to that complex molecule.
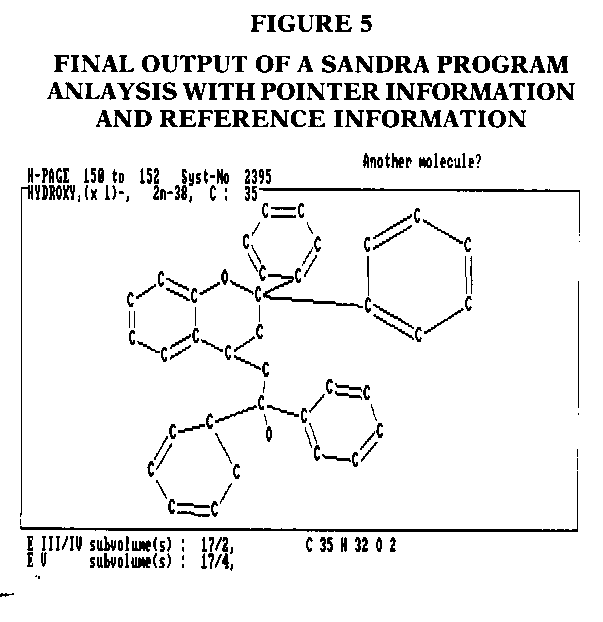
Figure 5 shows the output of the program after the analysis is finished. This example, as well as the four previous figures, are direct screen dumps, onto a standard PC printer, using the print screen (Prt Sc) command. The compound chosen, a real chemical, is a diphenyl ethanol derivative I found by randomly thumbing through the Beilstein Handbook volumes. Its molecular formula is C35.H30.O2. The output information from the program, as seen in Figure 5, contains a good deal of pointer information. The pointers are: H-page (a range of 150 to 152), System number (2395), degree of unsaturation of the chemical compound (2n-38), and the number of carbons in the chemical compound (35 carbon atoms). The molecular formula of the molecule is also given in the lower right-hand corner.
SUMMARY
This article has discussed the Beilstein Institute's recent computer activities, covering both an existing product, SANDRA; as well as giving an introductory descri,~iomof the Structure and Factual Data files which will soon be available on DIALOG. These two files are likely to become two of the most highly utilized databases in the scientific community, and particularly in the chemical community. In the meantime SANDRA provides some computerized access to the wealth of Beilstein data.
REFERENCES
1. Milne, G. W. A., Potenzone Jr., R., and Heller, S. R., "Environmental Uses of the NIH-EPA Chemical Information System," Science, 215, pages 371-375 (1982).
2. Heller, S. R., "The Chemical Information Systems and Spectral Databases," Journal of Chemical Information and Computer Science, 25, pages 224-231 (1986).
3. Jochum, C., Wittig, G., and Welford, S., "Search Possibilities Depend on the Data Structure:
The Beilstein Facts," pages 43-52 in Proceedings of the 10th International Online Meeting
(London), December 1986, Learned Information, Medford, NJ (1986).
There are real, justifiable, and understandable diffferencesbetween the Chemical Abstracts Service databases and the forthcoming Beilstein Handbook of Organic Chemistry databases. The basis for these differences is fairly easy to understand. CAS is an abstracting and indexing service, which happens to be dealing in chemistry. The Beilstein Institute is a scientific organization whose goal is to produce a collection of critical reviews of all published and known data on the preparation and properties of organic compounds. Professor Freidrich Konrad Beilstein first published the Beilstein Handbook in the early 1880's while a professor at the Technological Institute in St. Petersburg.
This difference in approach is one reason that while the Beilstein Handbook covers the literature back to 1830 and CAS started only in 1907, there are probably twice as many compounds in the CAS Registry file as in Beilstein Structure file derived from the Beilstein Handbook. Over one hundred Ph.D. chemists at the Beilstein Institute critically review published data, and examine it for soundness, consistency and comparison with other reported findings. CAS abstracts is published with no evaluation, and often uses the author's own abstract rather than examine the reported results in any meaningful way. When indexing the information, rather than creating a scientific system of indexing, CAS has its own nomenclature, which often produces non-existent compounds when there is a need for a heading in the parent name or parent ring index for a compound. (I-am not the first person, nor do I expect to be the last one to discuss this problem of chemical and structural databases. For readers interested in further and more detailed discussion of these matters I refer you to the excellent chapter by Ernie Hyde (1) who has more years of experience in these matters than I am old.)
All this means is that the logic of a librarian and the needs of a librarian are not necessarily the same as that of a chemist. The real bottom line of this discussion is simple. The Chemical Abstract Service products are weekly publications that report what has been published, and as such are highly valuable to chemists. The Beilstein Handbook for Organic Chemistry, a critically~evaluated collection of factual data and their complete chemical structures, is a complementary publication to CAS. However, since it takes years to produce, it is not the place to go for very recent potential sources (i.e., bibliographic references) of scientific information, data, and knowledge.
The Beilstein Handbook, even in computer-readable form, will never be a timely source of chemical information. Both products, CAS and Beilstein, are needed, and should be readily and inexpensively available to the chemical community. (Certainly they will be readily available, but until their use is widespread among chemists, the costs for both will be high which I define as greater than $100 per hour.)
Hyde, E, "The Neglected Ingredlent in Chemical Computer Systems," Chapter 1, pages l-8, in "Computer Applications in Chemistry," edited by Heller, S.R., And Potenzone Jr., R., Elsevier, Amsterdam
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}