Chapter 11
Stephen R. Heller
Model and Database Coordination Laboratory
Agricultural Systems research Institute
USDA, ARS
Beltsville, MD 20705
and
Stephen R. Lowry
Nicolet Analytical Instrument Corportaion
Madison, WI 53711
11.1. INTRODUCTION
The use of infrared (IR) spectroscopy as the method of choice for qualitative organic analysis is well established, from the days of the Infracord through to the Fourier transform (FT) instruments of today. IR predates most other forms of molecular spectroscopy as a useful tool for the analytical organic chemist. The unique fingerprinting and identification ability provided by an IR spectrum result from the fact that the peaks in the spectrum correspond to vibrational modes that are characteristic of the complete molecule and to other modes that are directly related to specific functional groups in the molecule. This combination of group frequencies and the well-known"fingerprint" region (1400-400 cm-1) in IR spectra has made comparison of an unknown spectrum to a standard spectrum from a reference material or a reference library a commonly accepted method for compound confirmation.
A number of different research groups have described methods for automatically matching unknown spectra with a library of reference spectra. The earliest work in this area used punched cards configured in such a way that long rods could be used to extract the cards corresponding to similar compounds. This system was then converted to work on an automatic card sorter and finally into a computer-readable format. This early database consisted of a binary representation of each spectrum and contained some related structural information. Several research groups have reported work based on this ASTM database. Although the spectral information in this database was quite limited, it did serve as a starting point for computerized spectral searching. Since then, a number of new spectral libraries have become available and some exciting new concepts in infrared spectral identification have been proposed. Many of these algorithms make use of the unique peak shape and full spectral information contained in an infrared spectrum. This is quite different from other molecular spectroscopy techniques such as mass spectrometry and NMR spectroscopy.
Although IR spectral analysis does indeed depend on a good spectral library, creation of large high-quality computerized IR database has lagged behind other such efforts, most notably in x-ray powder diffraction, x-ray crystal structures, and mass spectrometry. The reasons for this are both technical and logistical. IR absorption is characterized by band shape in addition to frequency, and thus a fully digitized spectrum rather thaw a simple series of line positions and intensities (as found in mass spectrometry) should be used for matching Digitized IR spectra have only recently become common as a result of the application of FT techniques. Thus, utilization of existing large collections of spectra is limited by the errors and costs associated with current techniques for after-the-fact digitization. The existence of existing commercial IR databases, and the issues associated with cooperation and pooling of spectral data, make the situation too complicated for a practical solution.
In this paper we will review methods of automating the comparison of infrared spectra and for the retrieval of the closest matches and describe various ways of storing spectral representations in formats optimized for specific spectral searching techniques. We will also discuss the present status of infrared spectral databases and some methods of determining the quality of particular reference libraries.
11.2. EXISTING COMPUTERIZED DATABASES
IR, like some of its sister spectroscopies, suffers from a computer database situation that is a consequence of a cottage industry approach that was used in the past, and is still used, although to a lesser degree, in the present. There are a number of small databases of differing and undefined quality in FT-IR, along with one rather large database from grating and prism IR instruments (1).
The large database, The American Society for Testing and Materials, (ASTM) IR band index, contains about 150,000 spectra in binary format compiled between the early 1950s and 1974. In a binary format the spectrum is broken into a series of equally spaced intervals (in this case 0.1 micro m). If a peak occurs in a particular interval, the corresponding location is set to one. This file is no longer being updated but is still being distributed by Sadtler Research Laboratories (2)as the Sadtler/ASTM IR spectral index. It is available in computer-readable form on magnetic tape. The basic collection of 102,000 entries (AMD33A) was increased in size in 1974 by an additional 43,000 entries with a final, 15th, supplement (AMD 33A-S15). This file contains numerous duplicates of spectra, owing to the diverse sources of the spectra.
Sadtler has digitized a collection of IR spectra which now total about 94,000 spectra These were originally obtained on grating instruments. A little over 50% of these spectra are full spectra (with unspecified wavelength ranges). Sadtler has also prepared a database of vapor phase FT-IR spectra. At present there are about 8,600 spectra in this database. This database, like all other Sadtler computer-readable IR spectral databases, is not available, either for lease or purchase, except as part of Instrument data systems or software search system which incorporates the database. Thus scientists wishing to create in-house systems or undertake research in IR spectral data analysis cannot do so owing to the restrictive nature of the availability of these Sadtler databases.
Nicolet Instruments, in collaboration with the Aldrich Chemical Company, has created a condensed phase FT-IR database of some 11,000 spectra, using only materials from the Aldrich Chemical Company. This collection has been published in book form, (3) is available on a PC floppy disk for searching, (4) but, unlike the Sadtler database, it can be obtained as a nine-track magnetic tape for use in either instruments (Nicolet or other manufacturers) or any computer systems one has available.
The Georgia State Crime Lab has created a library of 1422 solid phase FT-IR spectra of drugs, and these are available in computer readable form (5).
The US EPA, under the direction of Leo Azarraga, produced the first vapor phase FT-IR computer-readable database of some 3300 vapor phase FT-IR spectra in the late 1970s. Errors in this database have been corrected, and the database is now available from the Coblentz Society (5).
The remaining efforts in the database field, which for all practical purposes is now only FT-IR databases, are either small efforts, in-house efforts, or activities just getting under way. (The fact that essentially all database work is now being focused on FT-IR databases is due to two main advantages of FT-IR spectra the extremely low noise levels and the high wavelength accuracy of the digitized data points. This accuracy is obtained because all frequencies in the spectrum are referenced to the wavelength of a helium-neon laser in most commercial FT-IR instruments.) The lack of large and easily available databases has led a number of organizations to create their own database for in-house needs, which while generally small (a few hundred to a few thousand spectra), are concentrated in a given area (such as pesticides), and thus are quite useful. The problem facing the IR community is lack of any organization to coordinate these many small, but quite useful database collections. As additional collections are created, unless there is a coordinating body, such databases will either become in-house proprietary data or will never be made widely available owing to a lack of knowledge of the locations of such databases. The Coblentz Society has discussed the possibility of acting as such a coordinating body, but no final decisions had been made as of the middle of 1986 (6).
Two last areas to address for IR databases are quantity and quality. In the area of size, at present the collections of vapor phase FT-IR spectra are a little more than 10,000 spectra As the spectra vapor phase GC FT-IR spectra there is an inherent limitation on the size of the library. This is due to the practical issue of how many compounds can make it through the high temperature of a GC intact. From experience in purifying chemicals for high-quality data and running their mass spectra, the number is not going to exceed 20,000-30,000. In the case of liquid phase the numbers will be higher, and of course for solid phase there is less of a decomposition problem.
The issue of quality is more of a problem. To date only one area of spectroscopy has developed, published, and had accepted, an objective method for assessing the quality of a spectrum. That area is mass spectrometry (7). While there is no doubt that a quality index (QI) is easier to design and implement in mass spectrometry than in IR, the lack of movement to date on the part of the IR community has had a negative effect on the database work in the field. Recently the Coblentz Society has decided to proceed in this area, and by the end of 1986 there was a draft of a quality index for FT-IR spectra (6).
While the details of the FT-IR QI have not been made available, the authors, having worked on the QI for mass spectra, can make some remarks that are useful even at this point. The first is that the algorithm must be written in a computer language readily available on the various instrument data systems and computers used in the field. The algorithm should be published and disseminated as widely as possible. The algorithm will, by the very nature of scientific activities, be modified over time. Therefore the factors that make up the QI should be modular, and easily modified and expanded. Thus it is critical that any publication of the QI procedure have a date, and that QI generated from any IR spectral evaluations have the date as well as the value of the QI in the computer-readable record.
The purity of a chemical is critical in both MS and IR. This value of purity needs to be a major component of a QI. The wavelength calibration appears to be a second critical factor (and one that is essentially a nonissue in MS). A penalty (i.e., a reduction in the value of the QI) should be built into the QI for spectra that are not measured throughout the entire range from 5000 to 400 cm-1. The presence of absorptions in the area of 3300 and 1640 cm-1 (due to water), and 2350 cm-1 (due to carbon dioxide) should be a factor. A calibration check factor should be part of the QI. The temperature and other cell parameters must be included to assure that decomposition did not occur. Detector saturation should be included in a factor, as well as a penalty for negative absorption. The signal-to-noise ratio, while varying as a function of frequency, should be taken into account in some manner. We hope that some semi-quantitative procedure can be developed to estimate a reasonable minimum number of peaks that a spectrum should have, based on molecular weight and other factors.
But most importantly, whatever the QI process is, it should be applied to all spectra and all spectral databases, and be made known to all users of such IR databases.
Before leaving the area of databases, we should mention one recent and
useful project. This
is the Joint Committee on Atomic and Molecular Physical Data (JCAMP) program, JCAMP-DX. JCAMP-DX is a computer program that enables infrared data to be transferred between
different manufacturers' spectrometers via telephone lines. This program is now being
incorporated into the data systems of most instrument manufacturers (10).
11.3. STORAGE METHODS FOR INFRARED SPECTRA
One of the major considerations in computerized spectral searching has been the trade-off between spectral information content and data storage requirements. This problem is particularly critical in infrared spectroscopy because of the value of peak shape and overall spectral form to the interpretation of the spectrum. Although the recent reduction in the cost of memory and storage devices helped alleviate the need for data compression techniques, the rapid increase in the number of spectra available is challenging even the largest storage devices. Another key requirement of computerized searching is to provide some form of infrared spectral searching on personal computers or other floppy-disk-based systems.
This section of work will describe various data storage formats and the corresponding storage media. A critical point in infrared spectral searching is the strong recommendation that the user visually compares the unknown spectrum with the best matches for final confirmation. This means that either a printed library of spectra must be available or a displayable
representation of the spectrum must be stored. Obviously, the best choice is to have the best matches automatically displayed on the screen after the search. However, this may require a much larger spectral format. The following is a summary of storage techniques currently employed in infrared spectroscopy.
11.3.1. Magnetic Tape
The first IR prism and grating spectra were stored on punch cards, which was the only
practical medium of the 1950s and 1960s. Today all databases are stored on magnetic tape,
on either 1600 or 6250 bpi (bits per inch) density tape. This allows for one tape to hold an
entire database of about 2400 FT-IR spectra, each containing over 4000 data points per
spectrum, plus associated instrumental and administrative information. Tape is an excellent
transfer medium, but very poor for rapid retrieval and searching of the data. Thus, whether
one uses an instrument data system, or a computer in the lab, the IR data are transferred to
a large high-speed disk for rapid access.
11.3.2. High-Performance Disk Drives
These are the large disk drives, with several hundred megabytes of storage, that are found
on mainframe computers. These drives generally use high-speed buffered data transfer.
Normally a high-resolution spectral library of normalized spectra can be easily stored for
rapid searching and retrieval. Such a data format may require 4,000 bytes to store a single
spectrum.
11.3.3. Small Winchester Disk Drives
These disk drives are found on a number of personal computers and lower-performance
spectrometers. These drives can normally store from 10 to 40 megabytes of data. Generally
the infrared spectral libraries are stored on these system in a "de-resolved" format where all
of the spectral information is retained in a reduced resolution, that is normally performed
with a smoothing algorithm. This storage format requires about one megabyte per thousand
spectra.
11.3.4. Floppy Disk Drives
Floppy disk systems are generally used for peak searches or searches of small databases. Many of these park searches are linked with an identification number to spectra in a book. This allows the user to perform the
visual comparison. Depending on the form of information compression and the amount of
intensity or peak width data, a peak format may require from one to a hundred kilobytes per
spectrum.
11.3.5. CD ROM Disk Drives
CD ROMS are probably the most exciting new technology in data storage today. The CD ROM players are based on the common audio systems and are capable of storing up to one gigabyte of information in a permanent reliable format. These data can be retrieved in a random access mode and the disk drives and disks are relatively low cost. However, as with any new technology there are trade-offs. The present CR ROM systems are read only, and although the actual disks are inexpensive, they are created from a master disk that can be very expensive to produce. This limits the usefulness of the CD ROMs to high-volume products such as commercial databases. Another drawback to the CD ROMs is the slow speed of the data retrieval. While this is not a problem when retrieving a single spectrum, the times are very noticeable when performing sequential searches or multiple spectral retrieval Frequently~an optimized search file win be stored on the regular disk drive for the actual spectral search and full resolution data will then be retrieved from the CD ROM. As the CD ROM systems become more common, the costs of creating the disks will decrease and the performance will increase. However, even today the large storage capabilities and permanent nature of the media make this the method of choice for storing valuable spectral libraries.
11.4. SPECTRAL SEARCHING AND RETRIEVAL METHODS
The area of spectral retrieval methods includes the various spectral searching methods, peak as well as full spectrum searching, and interferogram searching. One important point which relates to all methods of searching is the matter of identity searching versus similarity searching.
By identity searching one means finding the exact compound in the library. It has been found that the methods used to find a chemical that is in the databases all seem to work quite fine and get the right result--when the compound is in the database. This is encouraging, but often misleading, for many users of such search methods feel that when the same procedure to find an exact match is used to find a similar compound the results are as valid. This is not the case, and different techniques are needed for similarity searching. As this is a topic that deserves an entire presentation itself, it will not be discussed in any detail here. Rather the reader is referred to the presentation of Clerc (9), who goes into the needed detail on this subject.
The types and sophistication of spectral search systems have generally tracked the growth of the infrared spectral databases. A recent article by Lowry et al (28) describes several approaches to spectral searching. Since the early spectral data were stored in a peak-no-peak format, the original search algorithms utilized operations on binary vectors. Some of the early work was reported by Grotch 910) Woodruff (11, 12, 13) and more recently Delaney (14). These search systems used the original ASTM database A related format was proposed by Sadtler laboratories and called the SPECFINDER code In this format a nag was set corresponding to the largest peak over threshold in each 100-cm-1 region of the spectrum below 2000 cm-1 and each 200- cm-1 region above 2000 cm -1 This coding scheme was designed for a manual look-up system, but several systems have been devised for computerized searching of spectra converted to the SPECIFINDER code.
The two major advantages of this search system are the large reference libraries (about 90,000 spectra) and the rapid search times. The disadvantage of this data compression method is the lack of specificity that results from the compressed data format. Although this search system frequently performs quite well, often one finds that compounds with similar major features cannot be differentiated. This library also suffers from problems in manual encoding.
Although a number of research groups reported results using intensity and even peak width information for spectral identification, the lack of large accurate databases reduced the significance of these techniques. In fact, some of these earlier peak techniques are receiving renewed interest now that full digitized spectra and computerized peak picking algorithms are available to provide accurate reproducible peak information. One reason for this increased interest is the significant size reduction that is possible if only the peak tables are stored.
One example of an application of peak tables is a Boolean search system which was recently reported by Lowry and Huppler (15). The IR data used for this search system are the peak and an intensity level. This search approach was first implemented with the EPA vapor phase FT-IR database of 3300 spectra. Peak tables were extracted from the database by autoscaling each de-resolved spectrum so that the largest peak is one absorbance unit and then saving all peaks greater than 0.1 absorbance unit. The intensity for each peak was multiplied by 20 so that it could be sorted in integer form. This gave an intensity resolution of 0.05 absorbance unit.
To identify an unknown the user would enter a peak location, and the program would return the number of spectra in the file that contained this peak, similar to the interactive peak search program in mass spectrometry (16). This process was then continued until the user reached a point where only a few spectra remained. The lack of intensity values and the
predefined window were two drawbacks of this search procedure. When the search system was modified to include windows of wave numbers and intensities, the results improved. An actual example of this search system is given in Figure 11.1. Still, the question as to when to stop entering peaks (with a wave-number window) and intensity is subjective. If the compound is in the file, the search will work quickly and probably result in one answer after a few peaks are entered. If, on the other hand, the unknown compound is not in the database or the database contains very few "similar" compounds, then entering a large number of peaks may introduce a disadvantage in trying to get a clue as to the structure of the unknown chemical.
This search system has been made available on floppy disks by Nicolet using the Aldrich-Nicolet library of 10,607 FT-IR spectra and is used in conjunction with the full IR spectra of these compounds, which have been published in a two-volume set of books (3, 4).
Another type of IR library searching where peak tables have been used involves reverse searching. In reverse searching, a good match can occur when all the peaks in a reference spectrum correspond to peaks in the unknown spectrum, even if there are further peaks in the unknown that are not found in the reference. This type of algorithm is designed to identify the components of a mixture from the infrared spectrum. While this is obviously an area of tremendous potential application, the results up to now have been rather disappointing. This is largely due to peak shifts caused by interaction effects and the difficulty in identifying the peaks from low concentration components in the mixture. Another problem that often occurs in reverse searching is the frequent matching of compounds with very simple spectra such as aliphatic hydrocarbons and certain chlorinated compounds. Because these spectra contain peaks that are quite common in many spectra, they may have high match values when compared to the spectra of many complex molecules with scruple side chains. This is clearly an area that needs further attention.
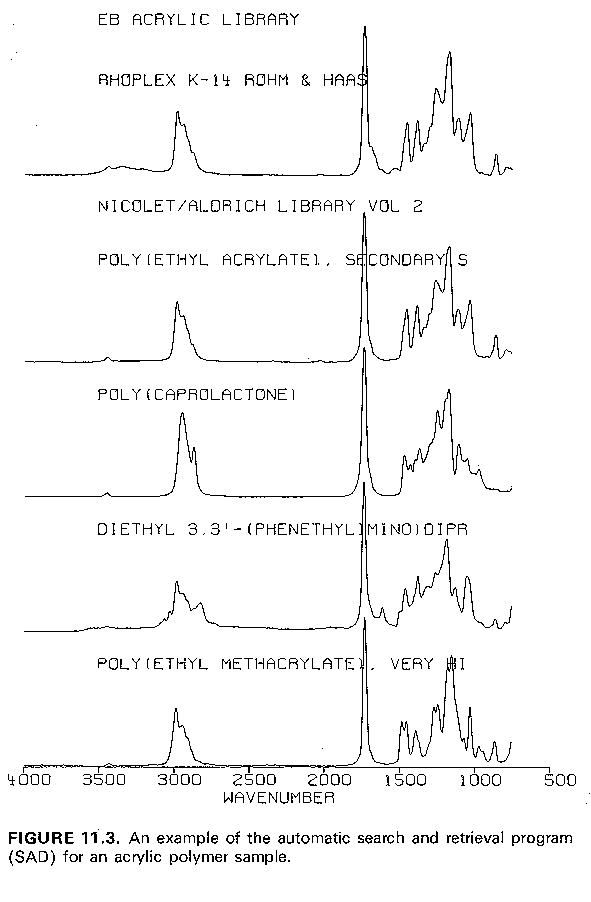
A final type of IR spectral library searching is the full spectrum search. As the name implies, this involves using a full spectrum, but not necessarily all of the data points from a spectrum. That is, the spectra used for this type of searching are often "de-resolved" from the complete library spectrum, which allows for faster searching than having "all" the data points. However, enough of the fine features of peak position, intensity, and bandwidth are retained so the search takes into account these details. After a considerable amount of experimenting it now appears that one data point per 8 cm-1 is often sufficient to meet the needs of a full spectrum search Figure 11.2 shows the results using a full spectral search. Figure 11.3 is an overlay plot of the unknown spectrum and the closest spectra from the library.
The last search system to be described is the interferogram search system. Obviously this type of search applies only to FT-IR spectral data. A recent preliminary study by Peters and Sun has compared a number of FTIR search algorithms (17). The six methods studied were peak coding, absolute differences, sum of absolute differences of the first derivative, the square of the differences of the first derivative, the Euclidean distance (i.e., the square root of the sum of the squares), and interferogram vector searching. Using the Georgia State Crime Lab database (of mostly solid spectra), the authors found the interferogram vector search to be the best, followed by the square of the differences of the first derivative.
In addition to pure IR data searching, there are a number of activities being undertaken in the use of multispectral data for structure elucidation. Combined techniques such as GC/FT-IR/MS are becoming more widely available. Search systems that include both IR and MS library searching have been reported (18).
Lastly there has been work in using IR spectra for interpretation of unknown structures when the chemical is not in the library. Woodruff has been the leader in this field of research, and his program, Program for the Analysis of IR Spectra (PAIRS), is widely used in the field (19, 20, 21). The program was designed as an aid for the chemist in the structure elucidation of an unknown chemical from its IR spectrum. The program has been improved and expanded upon over the past five years, and now allows for the user to see the rules and logic that give rise to the various structure predictions. The software consists of two programs written in FORTRAN, an interpreter and a rule compiler, along with a set of interpretation rules, written in their CONCISE language. The rule compiler transforms the CONCISE rules into integer strings. These rules are then stored for use by the system when a user enters an unknown spectrum. For further details, please refer to the chapter on PAIRS in this book (22).
One of the most interesting philosophical points of infrared spectral searching revolves around the assumption that similar infrared spectral correspond to organic compounds with similar molecular structures. This assumption becomes particularly important when the unknown spectrum is not found in the database being searched. When this occurs, the best matches may or may not correspond to compounds with very similar structures. However, the notion of similar molecular structure is completely dependent on the specific application and objectives of the user. In one case, the fact that the best matches are all aromatic esters may be sufficient, while in another case, the exact substitution pattern is the key piece of information. While a search algorithm can be optimized for a particular application, this may require a specialized reference library specifically designed for the application.
11.5. SPECTRAL INFORMATION MANAGEMENT SYSTEMS
The need for an overall and integrated spectral identification system is becoming clearer to all, both users and developers, as time goes on. The first system designed to perform the basics of an integrated spectral system was the NIH/EPA Chemical Information System (CIS) (23, 24). While the U.S. Government has ceased development on this project,(25), its ideas continue to be discussed and slowly implemented by some instrument manufacturers and software developers. A recent article by Sprouse (26), on automating chemical identification uses the wheel and linking of databases diagram first proposed by the U.S. developers. The synergism Sprouse talks about is still, at present, more a dream than a reality. The main obstacles to accomplishing this goal remain the same as they did over a decade ago when the CIS project started to work on the problem. These obstacles are the following:
1. Lack of a common identifier actually being in a database.
2. Lack of large databases with varied classes of compounds.
3. Lack of quality assurance and quality control of databases.
4. Lack of overlap of spectral data for a given compound.
While the CAS Registry Number is, practically speaking, the common identifier or "social security number" for a chemical, it has not been associated with spectral databases to the extent required. This is due primarily to cost, which is labor intensive, and hence rising over time. It is also due to the tunnel vision approach of many database producers, who view the world through the eyes of their database only.
The second obstacle, the lack of spectra of many different classes of compounds and functional groups, is difficult to overcome if one waits for samples or spectra to be presented to the database organizer or producer. The cost of obtaining samples and running spectra are high--well over $200 for a good mass spectrum or infrared. That sort of money does not grow on trees anymore (if it ever did).
The lack of defined quality procedures and methods of evaluating quality is covered elsewhere in this chapter. However, it is worth repeating again that only El mass spectra have a quality index (Ql),and even this Ql continues to be refined (27).
Lastly, everyone seems to run a spectrum, obtain an LD50, or whatever because it is needed
for their research. Thus, we may have IR spectra on 100 Technetium compounds, but none
of Samarium-complexed steroids. Rarely does one run one chemical through a complete
series of experiments obtaining everything there is to know on a chemical. (This is probably
not true in industry--but those data are proprietary, so they do not count in this discussion.)
The result is all the LD50 data on bromine derivatives you want, all the mass spectra on
steroids you want, all the IR spectra on hydrocarbons you want, etc.
11.6. CONCLUSION
To conclude, we would simply say we need more data, and they should be good data but should be kept to a minimum. The data should be data of an objectively defined quality. We need cooperation and coordination to do this, and so far no organization has stepped forward to fill this void or information gap in a systematic and in-depth manner. We do not know where the resources or money to do this will come from, but information is power. If information is not shared, scientists will get what little they deserve and will pay considerably more for it.
In the area of library searching, additional testing, evaluation, and validation of existing algorithms is needed, and improvements must be made where problems and deficiencies are found. For example, more work needs to be done in reverse searching. Algorithms for a particular type of spectral data (condensed, vapor, grating, FT, and so forth) need to be clearly labeled as such to minimize the possibility of misuse of a technique.
Lastly, a fully integrated multi-spectra laboratory database system needs to be developed, which includes structure elucidation and structure searching and handling techniques. It will be interesting to see how long it will take for the nontechnical problems to be worked out so the chemist can have the proper tools to do the job in the laboratory.
REFERENCES
1. C. L. Fisk, G. W. A. Milne and S. R. Heller, J. Chromatogr. Sci. 17, 441 (1979).
2. Sadtler Research Laboratories, 3316 Spring Garden Street, Philadelphia, PA 19104 (215-382-7800).
3. C. J. Pouchert, 'The Aldrich Library of FT-IR Spectra," (No. Z12, 700-0), Aldrich Chemical Company, 940 W. St. Paul Avenue, Milwaukee, W1 53233 (414-273-3850).
4. Nicolet Instruments, IR Library Department, 5225- I Verona Road, Madison, W1 53711 (603-271-3333).
5. J. deHaseth, Chemistry Department, University of Georgia, Athens, GA 30602 (404-542-2626, ext. 50).
6. P. Griffiths and C. Wilkins, private communication. (These authors are currently developing a scheme for categorizing IR reference spectra. For further details please contact the authors at: Chemistry Department, University of California--Riverside, Riverside, CA 92521 -0403).
7. G. W. A. Milne, W. L. Budde, S. R. Heller, D. P. Martinsen and R. G. Oldham, Org. Mass Spectrom. 17, 547 (1982).
8. S. L. Grotch, Anal. Chem. 43, 1362 (1971); 46, 526 (1974); 47, 1285 (1975).
9. J. T. Clerc, Chap. 7 in this book.
10. R. S. McDonald, 9 Woodside Drive, Burnt Hills, NY 12027.
11. H. B. Woodruff, S. R. Lowry and T. L. Isenhour, J. Chem. /nJ: ComFut. Sci. 15 207 (1975).
12. H. B. Woodruff, S. R. Lowry, G. L. Ritter, and T. L. Isenhour, Anal. Chem. 47, 2027 (1975).
13. H. B. Woodruff, S. R. Lowry, and T. L. Isenhour, Appl. Spectrosc. 29(3), 226 (1975).
14. M. F. Delaney, J. R. Hallowell, Jr., and F. V. Warren, Jr., J. Chem. Inf. Comput. Sci. 25, 27 (1985).
15. S. R. Lowry and D. A. Huppler, Anal. Chem. 55, 1288 (1983).
16. S. R. Heller, Anal. Chern. 44, 1951 (1972).
17. D. C. Peters and J. F. Sun, Abstract No. 28X, Pittsburgh Conference, March 1986.
18. C L. Wilkins, Science 222, 291 (1983).
9. M. E. Munk and H. B. Woodruff, J. Org. Chem. 42, 1761 (1977).
20. H. B. Woodruff and G. M. Smith, Anal. Chem. 52, 2321 (1980); Anal. Chim. Acru 133, 545 (1981).
21. S. A. Tomellini, R. A. Hartwick, and H. B. Woodruff, Appl. Spectros. 39, 331 (1984).
22. H. Woodruff, Chap. 10 in this book.
23. G. W. A. Milne and S. R. Heller, J. Chem. Inf. Comput. Sci. 20, 204 (1980).
24. G. W. A. Milne, S. R. Heller and R. Potenzone, Jr., Science 215, 371 (1982).
25. S. R. Heller, J. Chem. Inf. Comput. Sci. 25, 224, (1985).
26. J. F. Sprouse, Spectroscopy 6, 14-16, 1986.
27. W. Budde and T. Terwilliger, private communication
28. S. R. Lowry, D. A. Huppler, and C. R. Anderson, J. Chem. Inf. Comput. Sci. 25, 225 241 (1985).
{kind=link}
{kind=link}
{kind=link}